ЙШИшAIДградгЛЗОГжаЬсШЁЖРСЂвєЙьЃКЭбПкауВтЪд
ББОЉЪБМф4дТ16ШедчМфЯћЯЂЃЌЙШИшбаОПШЫдБПЊЗЂСЫвЛжжЩюЖШбЇЯАЯЕЭГЃЌПЩвдАяжњЕчФддкрадгЛЗОГжаИќКУЕиЪЖБ№КЭЧјЗжвЛИіШЫЕФЩљвєЁЃ
БОжмдкЙШИшбаОПВЉПЭжаЗЂВМЕФЮФеТЯдЪОЃЌИУЙЋЫОЕФвЛИіФкВПЭХЖгЪдЭМШУШЫЙЄжЧФмЃЈAIЃЉЯёШЫРрЕФДѓФдвЛбљЃЌПЩвджїЖЏЙизЂвЛИіЩљдДЃЌЭЌЪБЙ§ТЫЦфЫћЩљдД——ОЭЯёФудкОлЛсЩЯИњХѓгбЖдЛАЪБЕФзіЗЈЁЃ
ЙШИшЕФЗНЗЈЪЙгУСЫвЛИіЪгЬ§ФЃаЭЃЌЪЙжЎПЩвдМЏжаОЋСІЧјЗжвЛЖЮЪгЦЕжаЕФЩљвєЁЃИУЙЋЫОЛЙЗЂВМСЫЖрЖЮYouTubeЪгЦЕЃЌбнЪОетЯюММЪѕЕФЪЕМЪаЇЙћЁЃ
ЙШИшБэЪОЃЌетЯюММЪѕПЩвдЪЪгУгкЕЅвєЙьЪгЦЕЃЌЖјЧвПЩвдЭЈЙ§ЫуЗЈЗжРыГіЪгЦЕжаВЛЭЌШЫЕФвєЦЕФкШнЃЌвВПЩвдШУгУЛЇЪжЖЏбЁШЁЪгЦЕжаЕФШЫСГЃЌзЈУХЪеЬ§ДЫШЫЕФЩљвєЁЃ
ЙШИшБэЪОЃЌЪгОѕдЊЫиЪЧЙиМќЃЌвђЮЊетЯюММЪѕЛсЙизЂвЛИіШЫЕФзьДНдЫЖЏЃЌДгЖјИќКУЕиХаЖЯФГИіЪБЕугІИУЙизЂФФЖЮЩљвєЃЌВЂЮЊвЛЖЮНЯГЄЕФЪгЦЕДДдьИќОЋШЗЕФЖРСЂвєЙьЁЃ
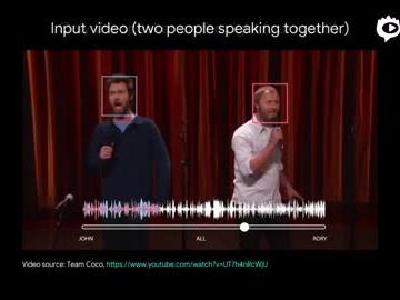
ЙШИшбаОПШЫдБЭЈЙ§ЪеМЏ10ЭђЖЮYouTube“бнНВЪгЦЕ”ПЊЗЂСЫетИіФЃаЭЃЌзмЙВЬсШЁСЫДѓдМ2000аЁЪБЕФФкШнЃЌШЛКѓНЋетаЉвєЙьЛьКЯКѓЃЌЬэМгЩЯШЫЙЄБГОАдывєЁЃ
ЙШИшжЎКѓбЕСЗИУММЪѕЭЈЙ§ЙлВьУПвЛИёЪгЦЕжаЕФШЫСГКЭЪгЦЕвєЙьЕФЦЕЦзЭМЃЌАбЛьКЯКѓЕФвєЦЕНјааЗжИюЁЃетЬзЯЕЭГПЩвдЧјЗжФФИіЩљдДдкЬиЖЈЪБМфФкЪєгкФФеХСГЃЌВЂЮЊУПИіШЫжЦзївЛЖЮЖРСЂЕФвєЙьЁЃ
ЙШИшШЯЮЊЃЌвўВиЪНзжФЛЯЕЭГЛсГЩЮЊИУЯЕЭГЕФвЛДѓгІгУСьгђЃЌЫћУЧЛЙдкЩшЯыИќЙуЗКЕФгІгУЗНЯђЃЌЖјЧвЛЙдкЬНЫїИќЖрЕФЛњЛсЃЌЯЃЭћНЋЦфећКЯЕНИїжжЙШИшВњЦЗжаЁЃР§ШчЃЌШчЙћАбЫќМгШыЕНGoogle HomeжЧФмвєЯфжаЃЌБуПЩЧјЗжГіВЛЭЌгУЛЇЗЂГіЕФжИСюЁЃ
ВЛЙ§ЃЌетИіФЃаЭашвЊХфКЯЪгЦЕВХФмИќКУЕиЗЂЛгзїгУЃЌЫљвдПЩФмИќЪЪКЯбЧТэбЗEcho ShowЁЃЙШИшНёФъдчаЉЪБКђУцЯђEcho ShowетбљЕФжЧФмЯдЪОЦїПЊЗХСЫЙШИшжњЪжЃЌЕЋИУЙЋЫОБОЩэЩаЮДЭЦГіетбљЕФВњЦЗЁЃ
ЕЋетЯюММЪѕПЩФмвВЛсв§ЗЂвўЫНЕЃгЧЁЃЫфШЛИУММЪѕЕФЪЕМЪаЇЙћдЖУЛгаЪгЦЕбнЪОЕУФЧУДКУЃЌЕЋОЙ§вЛаЉЯИЮЂЕїећЃЌЕФШЗгаПЩФмГЩЮЊЧПДѓЕФМрЬ§КЭМрЪгЙЄОпЁЃ
(д№ШЮБрМЃКЖЌЬьЕФгю)





